我差不多在16年初知道有DevOps这个概念,不过当时还是从《凤凰项目》那本书了解了些许传统IT如何去提高日常从研发到交付整个流程的效率的方法论。
近几年DevOps被落地的案例越来越多,据我所知道的一些企业,基本都或多或少落地了DevOps中的一些内容,所以这两年总感觉聊DevOps貌似变成了一个有点“不上档次”的事情。
DevOps是一个比较大的概念,所以真要去深究,非一日之功。正好上周在公司做了一场关于DevOps的入门分享,所以想用十篇文章分别从理念和技术两个层面来谈谈我对DevOps的一些理解以及这几年实践的一些内容。
理解一个东西我们总会用我们所熟知的一个东西进行对比,所以我们也采用这种方式,从传统入手,从熟悉的事情入手。这一篇先聊聊研发交付的内容。
传统研发交付流分为如下几个节点: 1、产品经理给出需求; 2、研发同学对需求内容做评估,比如可行性评估、工作量评估等; 3、评估完了之后开始研发,比较重大的一些需求可能会做技术设计和评审; 4、研发完了之后递交测试同学测试; 5、如果有用户部门的会涉及到用户验收; 6、验收完成后就安排预发环境的冒烟了; 7、最终完成生产上线过程。

从以上可以看到,一个需求,哪怕是一个小的变更,所涉及的流程还是挺长,而且在整个流程中还经常会发生一些状况,比如产品经理的需求变更,研发同学工作量评估少了,测试同学的重复性测试与研发同学bug解决的速度,研发同学开发测试环境部署出现状况,研发同学递交运维同学包和脚本出现的状况,运维同学发布过程中的问题等,在这么多的节点中,每一个节点其实都影响着整个研发交付的效率。所以在现实的需求交付过程我们都会发生如下图的情况:
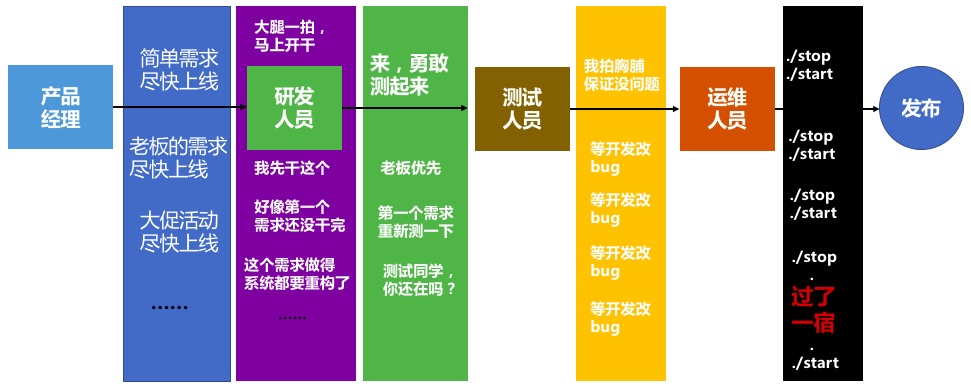
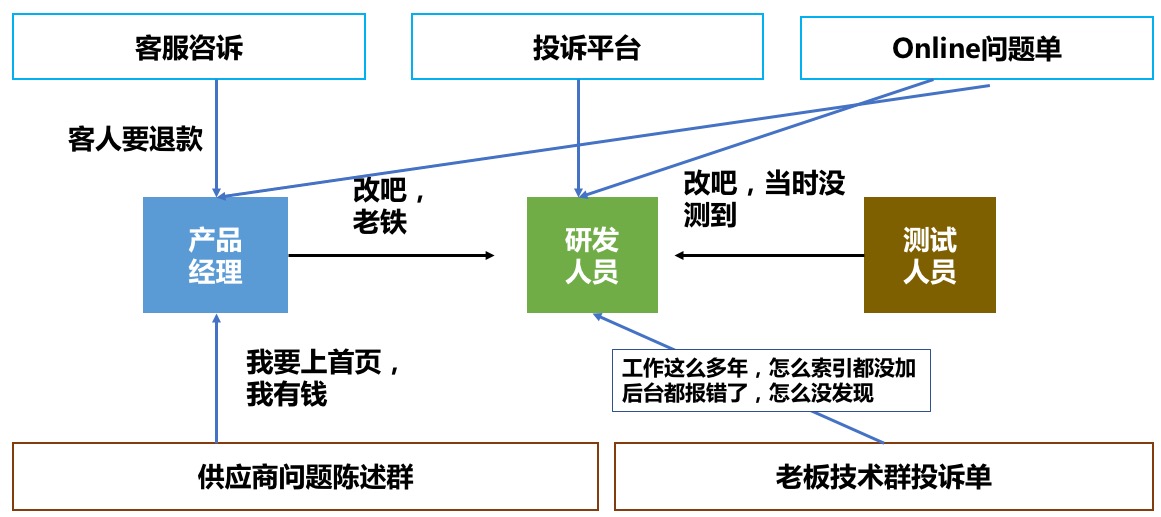
终于有一天,需求终于上线了,作为一直处于研发一线的我的经历,每次需求或者项目上线的时候,其实是兴奋且紧张的。然而,并不是每一次上线系统都健壮如牛,有些时候可能真是软的像面条一样。比如运维问题单的频繁报送,外部用户的投诉,问题不能及时去发现与解决,有些问题业务比IT更早地去经历从而影响用户体验等等。
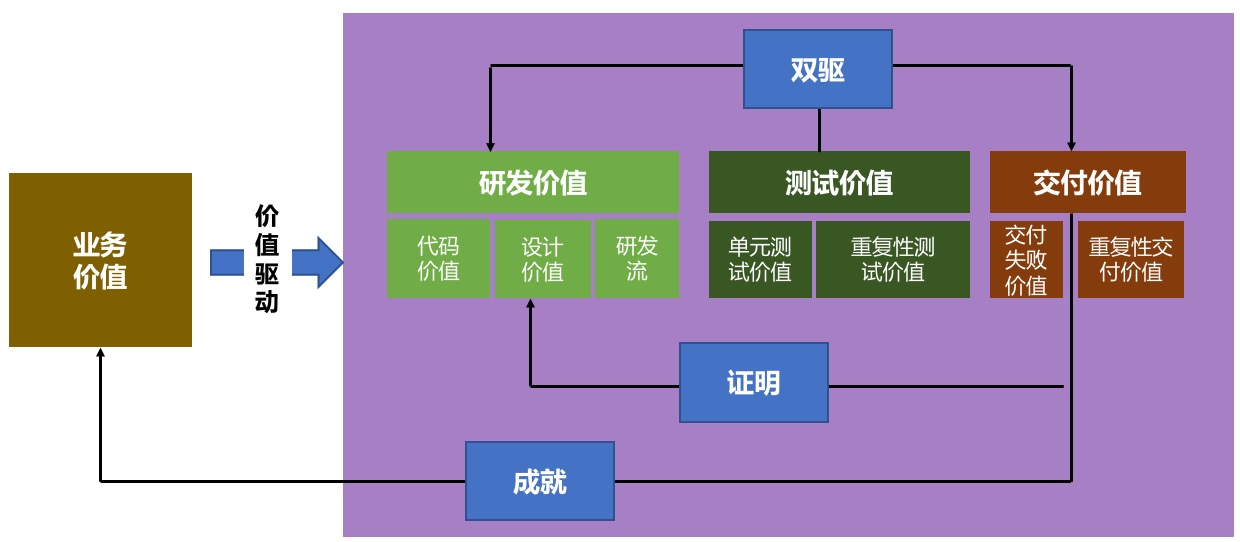
我个人观点,DevOps其实是一种理念+技术相互配合从而更快地去驱动业务价值的体系,而并不是仅仅是一个平台或者是一门技术。而对于IT来说,其实我们归根到底就是为了达成业务价值,即使是一些纯技术公司,本身也是业务,只是这个业务更加抽象。所以,在整个IT交付流程中,其实每一个节点都有其价值所在,而DevOps其实就是为了这些节点能够运转得更高效,价值也能够更快去达成。
聊完了整个交付流程,现在我们可以去深究研究每个节点的价值。 这一篇我们看下研发这个节点。 我们经常会听到相关非研发岗位的同学问研发同学为什么『零BUG的一次交付』怎么这么难,作为处于研发一线的我也经常问自己,到底是什么让我们像阿克琉斯一样,会因为『踵』的弱点,而导致幸幸苦苦所有的心血都白费,而且客户体验还变得很差。 研发同学一天的工作我把它归纳为三点: 1、创造BUG; 2、查找BUG; 3、解决BUG。 以上三点可能有点调侃的意味,但其实也能够体现出研发同学日常的工作。而且,研发同学在交付的过程中,也经常会有很多『世纪未解之谜』。 1、本地运行挺好,一测全部推倒; 2、这肯定是网络问题; 3、主机重启一下就好了。 所以,『零BUG的一次交付』怎么这么难?难道真是研发同学的能力有问题吗? 根据这么些年的研发经历看,『零BUG的一次交付』基本不存在! 我们来分析一下传统的研发同学在交付自己代码的一个过程。

正常一个稍有规模的企业,都会将自己的交付环境分为如上几套,研发同学在交付自己需求的时候也往往需要经历整个流程。我们先分析下,在开发这个节点,研发同学正常会遇到哪些问题。 我列举出如下一些遇到过的问题: 1、代码合并丢失。这个问题可能是一些较大的或者跨多人的需求研发过程中经常出现的问题; 2、配置还是本地的。传统开发中,我们很多配置信息都是放项目配置文件中的,有些时候可能都已经到验收了但是配置还是开发环境的; 3、需求变更。这也是一个产品经理和程序员之间相爱相杀的问题; 4、需求拆分。比如大版本中的某个需求突然不上线了,说起来,都是泪。
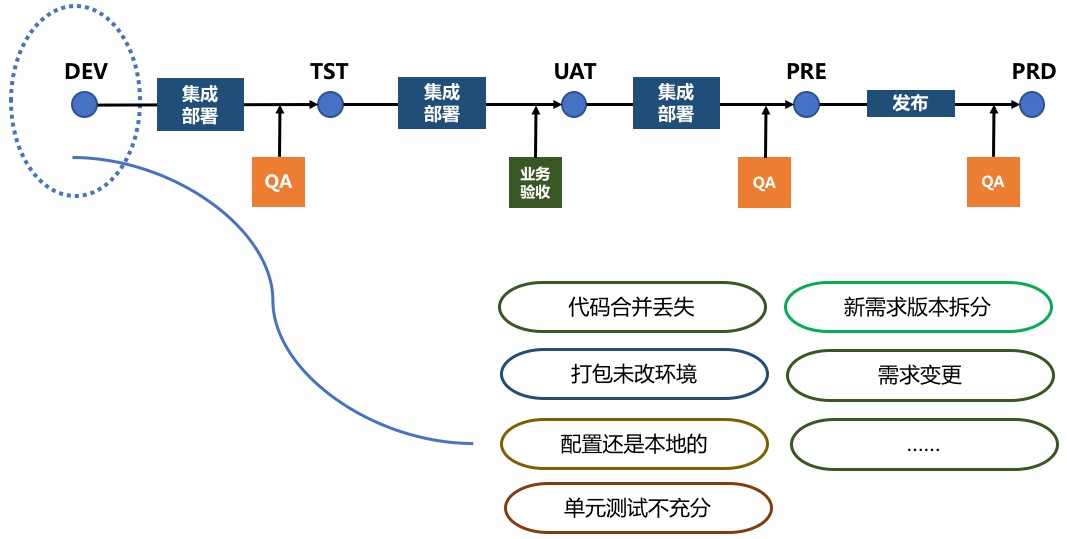
除了,在开发节点研发同学所会遇到一些问题,我们再继续分析下,在整个交付环境流中,部署环节上又会遇到哪些问题。 首先,我用传统的方式去验证了一次打包构建到服务器发布的过程。

我们可以看到时间还是挺冗长。而且我们可以发现两个点: 1、整个过程几乎串行人工,研发同学几乎不能去干其他事情; 2、碰上有紧急内容在测试或者验收,只能等待集成部署。 所以,这个节点其实又变相地降低了研发同学整个交付流的效率。 同时,我们在梳理一下在整个部署流程中会出现哪些问题。
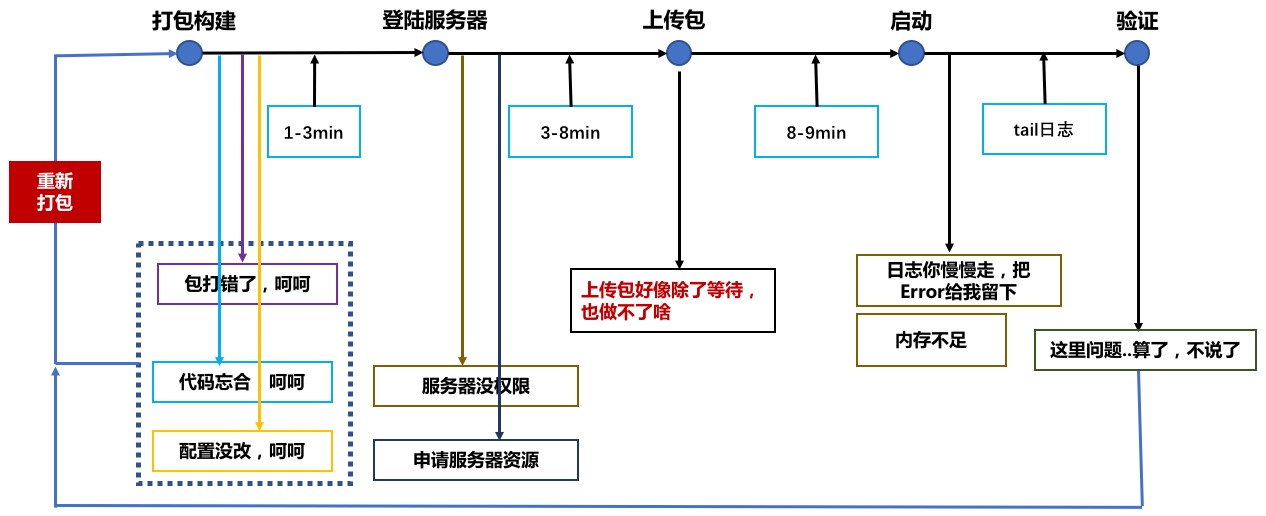
1、打包构建过程中,我们可能会碰到包打错了、代码忘记合了、配置没改等问题;
2、在使用主机期间,我们可能会发现服务器没权限、服务器资源不够了等;
3、上传包阶段我们除了等待好像其他也做不了;
4、到了真正启动阶段,我们可能还要通过肉眼去观察是不是有问题出现、主机各项配置是不是都达到预期的目标。
所以,我把以上的情况或者遇到的问题总结如下。
1、用重复打包构建证明代码是有问题的;
2、用重复部署证明打的包是有问题的;
3、用万年不变的方式看启动日志来证明当前这次部署是有问题的。
再精炼成两句话:Build for failure、Integrate for failure。
用一句比较流行的话升华就是:通过不断地失败来避免失败。
所以,从这里我们可以发现,失败其实是有价值的,每一次失败其实是为我们下次成功提前发现问题以及去找到出口。不过,我们有些时候其实是不想去承认失败,而且因为不想承认失败总会思维固化。我们一贯的思维是遇到失败去克服失败,其实我们可以在失败之前,让“别人”替我们先承担失败的成本。
那如何让别人去替我们承担失败的成本呢?
这个时候就逼迫我们去重新思考整个研发交付流,以及如何将『别人』置身其中去解决我们的问题。
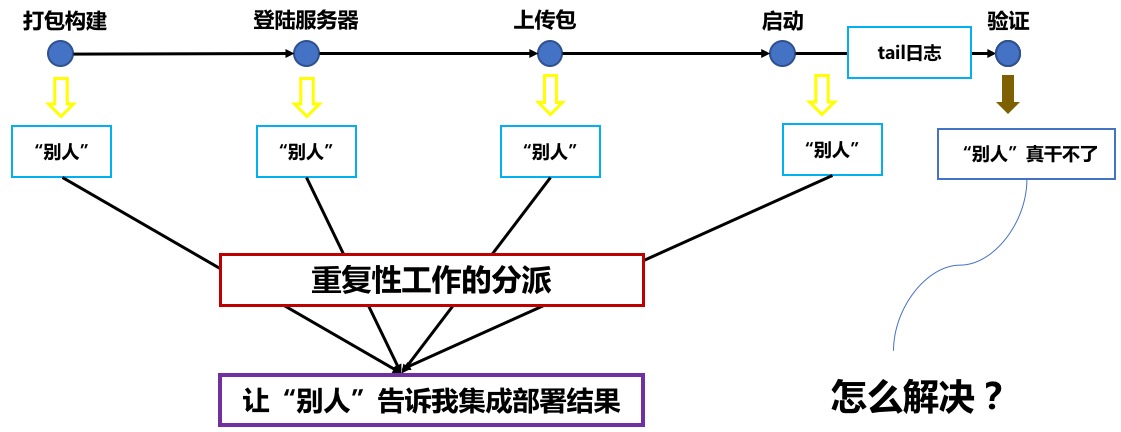
下一篇我们将继续来讨论这个交付流中我们还会遇到哪些问题。
—————–EOF——————