首先还是感谢这段时间家里那位主人的支持,鼓励我去学会分享,并且和我探讨怎么做好一个主题的分享。正如看到一位球友所说的,在碎片化的时代,按照主题研究的能力是我们需要具备的;可能还要加一句,如何更好去对研究的主题做分享也是一种需要不断去提升的能力。
下面我们进入正题。
前三篇我们主要还是围绕着从研发到运维整条线如何用DevOps的理念去解决影响我们研发交付效率的一些问题,整体来说,也涵盖了如今做DevOps的一些主流的方法论。那么今天我们再继续讨论一下DevOps方法论的最后一部分内容。
每当我们一个需求上线的时候,其实是真正考验我们的时候,这个时候才是见证你的系统和代码到底是健壮如牛,还是软的像面条一样。正如我们在第一篇所介绍的,以往的传统运维方式都是等问题出现了才会去考虑怎么解决问题,有些许后知后觉的意味,最终导致用户体验不是那么友好。 所以这就引申出一个话题,研发同学怎么快速地去获知到自己的系统出现了异常?
我时常听到一句话:敌军还有三十秒到达战场。然而对于一个大规模业务系统来说,三十秒才发现『敌军』貌似有点慢了?
那我们就来看一下,在我们的系统实际运行过程中,到底会有哪些因素导致我们系统异常。
我们先看一下日常我们发现系统异常的案例。 1、发现页面信息中抛出了异常的信息,日志一查,果真error了; 2、流量来的太快,系统根本来不及去应对,直接502服务器错误; 3、文件上传老是出错,一看磁盘满了; 4、貌似报内存溢出了,一看JVM频繁GC了; 5、redis老连接不上,一看集群宕机了 ……
当然,还会有很多很多,改编一个台湾电影的名称,《那些年我们遇到过的异常》。
所以,根据如上的这些生产的案例,我们倒可以从大的维度上将异常分为如下类别:
1、日志类别
我们生产中的输出日志正常会包括Error、Info、Warn等级别进行分类,其中以Error日志的输出更容易引起我们的关注。所以,见日志可查异常是我们日常生产运维的最重要的一种方式。
2、资源类别
资源类别涉及的内容就比较广了,比如当前主机的CPU是否超标了,磁盘是不是满了,内存是不是不够了,文件句柄是不是打开太多超了等,这些资源是系统运行真正的衣食父母。
3、网络类别 这块涉及的内容就比较广也难度也比较大了。往往也是企业里排查系统问题最难排查的一个类别。比如系统间访问异常可能是网络异常导致,DNS无法解析内部域名,网卡超了,带宽被占满了等等,可以说网络就像水一样,其是满足系统流动运转的重要保障。
4、中间件类别 这块其实涉及的也很广了,现在企业中正常会使用很多中间件去满足系统高可用、吞吐量的一些要求,比如依赖redis做缓存,通过消息队列做系统间的解耦,通过Nginx做反向代理以及动静分离等,所以中间件越来越成为IT中占重要地位的满足系统运转的资源与保障。 所以,从以上这些类别的划分来看,不谈业务节点的问题,光硬性的指标我们都会碰到很多的无法预知的异常。 那么怎么让异常触达到研发运维线能够相对的准确和准时? 所以,我的个人观点是,系统生产运行的合理监控与报警也是DevOps价值流中的重要一块,目前也有很多技术去专门解决这方面的问题,后面我在技术部分也会专门来侃侃。
接着我们再看另外一块内容,这也是近几年比较火的一个主题。 前几年有一本很出名的书叫做《反脆弱》,这是我近阶段最喜欢的一本读物,而且延伸出一句很有意思的话:杀不死我的必使我更坚强。其实就是表达了一种失败只是短暂展示了你的脆弱,但是一旦以『向死而生』的精神去面对,也许会变得比失败之前更强,当然也有可能更失败:) 读完了这本书后,我就思考,对于一个系统来说,我们能知道它最脆弱的时候是在哪里吗?它最脆弱的时候最终是宕机了还是能够去克服脆弱呢? 这么一想,我就想到企业里所做的故障演练。
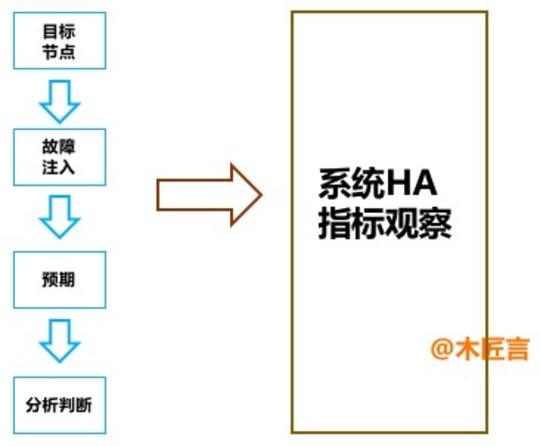
我们看下传统的故障演练的流程。 首先我们选择一个目标节点,比如某一台我们想进行故障演练的系统或者中间件; 接着我们对这个系统进行故障的注入,比如故意加大流量、创造异常等等; 然后我们分析一下我们『故意捣乱』的结果是不是与我们预期相符; 最后进行整体故障演练的分析与判断。 其实整体故障演练下来,就是来判别影响系统HA运转的指标因素到底有哪些。 这里我也对故障的会产生的点做了一个大概的罗列。 按照我们常规的一个互联网系统的物理架构模式,正常会分为流量进入层、应用层、数据层、操作系统本身以及影响的网络,正好与刚才所分析的监控指标一一对应。
我们看一下这些层次会发生哪些问题。
1、流量进入层 这层正常是面向于用户的第一个入口也就是流量的入口。所以时长会发生比如流量突增、网络被限流了、域名无法访问、静态资源访问不了等等;
2、应用层 影响应用层的指标就比较多了,比如业务异常节点,内存溢出,GC频繁,服务间调用异常等;
3、数据层 这里的数据层是一个广义的。比如ES、redis、mysql其实都属于数据层。时长也会遇到不少问题。比如redis宕机了,mysql宕机了,连接池占满了等。
4、操作系统层 操作系统根据刚才所监控的指标来看,比如CPU偏高、内存满了、服务器宕机了等。
5、网络层 这块是一个老大难的模块。比如网络丢包、网络瘫痪、网络中断超时、网卡打满了等等。 从以上可以知道,在故障演练的时候其实我们有很多故障是可以主动去注入来判别系统的运行状况。
所以最近几年就衍生了一个新的话题,混沌工程。 其实我的理解就是用数据来驱动故障演练,得到一次次的实验结果,从而改善系统的高可用指标。 那么这些实验的数据从哪里来呢? 所以我觉得混沌工程的第一个前提就是: 收集分析日常生产运行所导致的故障因素,通过精益数据分析,进行抽象。 那有了数据之后,我们肯定还要工具来驱动数据做实验。所以混沌工程的第二个前提就是: 以UI/脚本等方式进行工具固化乃至平台化去驱动故障数据运转。 有了以上的前提后,混沌工程进行还要遵循几个原则。 第一,需要在生产进行,因为生产是能够代表系统真实的运转情况,也能够去验证你的混沌工程成果是否合理;第二,遵循持续集成的理念,不断地通过实验去发现和总结,改善系统的时候也对后面的实验做数据依靠;第三,在实验的时候一定要控制系统的稳态,不能为了混沌工程而混沌工程。 因为混沌工程并不是一个必须条件,其只是让系统在生产运行更精确的一个手段。
支持,DevOps的我想阐述的一些理念就结束了。虽然其实DevOps还会有很多其他的领域涉及,但是相信大家看了这四篇文章,或多或少能触类旁通,结合实际的工作去进行逐步切入使用了。
那么,到底什么是DevOps呢? 这里我结合一些案例以及研究的内容,如下: 企业中的人将长期积累的流程规范通过统一的平台和工具链结合关键的研发交付文化(敏捷、互动协作、精益数据分析、指标可量化,当然还有知识传承共享)不断地驱动着研发交付达到持续集成和持续部署的目标。
讲了这么多的DevOps的理念,那如何去实现他们呢?目前又有哪些主流的工具去帮助DevOps的落地呢?接下来将会用六篇的文章去继续探索。
—————–EOF——————