今天是6月1日儿童节,想想现在的小孩确实是很幸福,父母都会送礼物和一起玩耍。但是转念一想,其实我们那时候也很幸福,到了这种季节,农村里总会有很多好玩的东西等着我们,那种乐趣并不是仅仅礼物或者高档的玩耍可以代替的。
今天闲着无聊,还有一个星期就要离开学校了。前段时间一直在看前端的东西,获得了不少新的知识。正好有那么几天没玩java了,因为看过Tomcat的源码,但是对于自己来实现一个这种类似的服务器,确实还是很有难度,所以今天就来尝试开发一个简单的web服务器。
从整个实验到最后,我觉得如果要做一个简单的服务器,还是需要掌握很多知识。当然这个东西也是特别考验一个人的能力,所需要学习的知识点如下:
基本网络知识、Socket编程、知道什么事服务器,应该怎样使用、Http相关的内容,其中包括各个
状态码的含义,用户在浏览器敲一个网址在内部会发生什么样的情况,文件的操作,当然,假如要做
一个比较好的,涉及到高并发处理的服务器还需要相关线程、并发处理的知识。 总而言之,自己做一遍之后,你才会发现,能够开发出类似于Apache、Tomcat这类产品的是真正的高手。
下面我就着手开发自己的小型服务器。
我们知道在tomcat中,我们总会将自己的项目部署在一个叫webapp文件夹下,那么我们也来进行类比。
首先,在我们的电脑中定义如下的文件目录,详细信息如下:
webapp
index.html//比如写入http://localhost:80/就会显示主页面
test
index.html//写入http://localhost:80/test就会显示主页面
webapp文件夹下的index.html中的内容为:
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"
"http://www.w3.org/TR/html4/loose.dtd">
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<title>Insert title here</title>
</head>
<body>
<h1>Hello server! Welcome</h1>
</body>
</html>
test文件夹下的index.html中的内容为:
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"
"http://www.w3.org/TR/html4/loose.dtd">
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<title>Insert title here</title>
</head>
<body>
<h1>Hello my home page! Welcome</h1>
</body>
</html>
因为仅仅是做一个简单的服务器,对于其他文件例如jsp、xml配置文件的解析等等我就暂时不做,先坐一个简单的demo出来再说。
因为,这次写的简单服务器时属于单线程模式的,所以就定义为SingleServer类。
整体的代码都在SingleServer类当中,并且实现Runnable接口。
###定义server的基本信息,代码如下:
public static int SERVER_PORT = 80;
ServerSocket server;
public SingleServer() {
try {
server = new ServerSocket(SERVER_PORT);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
System.out.println("The server does not start normally");
}
if (null == server) {
System.exit(1);
} else {
new Thread(this).start();
System.out.println("The server is running and the prot is:"
+ SERVER_PORT);
}
}
以上可以改进的地方:
1、在本段代码中端口号是硬编码,而在tomcat中端口号可以在xml文件中进行配置,这无疑增加了灵活性。
2、这里使用的模式是:一个用户连接服务器就开启一个线程,这在以后访问数量多的时候将会增加服务器的吞吐量,从而会发生很多阻塞、性能不稳定的问题。
###定义用户的工作
public void run() {
while (true) {
Socket client = null;
int contentLength = 0;
try {
client = server.accept();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
if (null != client) {
System.out.println("The client has connected to server
and the user is:"+ client);
try {
BufferedReader bf = new BufferedReader(
new InputStreamReader(client.getInputStream()));
System.out.println("The client sends the msg is\n---------");
String line = bf.readLine();
System.out.println(line);
String resource = line.substring(line.indexOf('/'),
line.lastIndexOf('/') - 5);
resource = URLDecoder.decode(resource, "UTF-8");
boolean bool = checkResource(resource,client);
if (bool) {
System.out.println("The directory is exist!");
} else {
System.out.println("The directory is not exist!");
}
String method = new StringTokenizer(line).nextElement()
.toString();
while (bf.readLine() != null) {
line = bf.readLine();
System.out.println(line);
if (line.startsWith("Content-Length")) {
contentLength = Integer.parseInt(line.substring(
line.indexOf(":") + 1).trim());
}
if (line.equals(""))
break;
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
} 代码虽少,但是需要掌握的东西还是很多。
1、首先,用户的访问信息都通过socket进行包裹。并且服务器获得用户的请求。
2、我们需要知道,在浏览器进行信息发送的时候都会有一定的格式要求,不过发送操作是GET还是POST,Content-Length,Connection状态,各个状态码。而以上的resource则是因为在我们文件头会有类似于这种形式GET /webapp/test HTTP/1.1的定义。
这里,顺便复习一下http协议。
###Notice
HTTP 0.9和1.0使用非持续连接:限制每次连接只处理一个请求,服务器处理完客户的请求,并收
到客户的应答后,即断开连接。采用这种方式可以节省传输时间。
HTTP 1.1使用持续连接:不必为每个web对象创建一个新的连接,一个连接可以传送多个对象。 http请求消息有如下几个部分组成:
请求行,消息报头和请求正文。
请求行中会包括相关浏览器的版本号,请求的方法,连接的方式等等。
浏览器也会提供相应的相应消息,其中包括:
Content-Length、HTTP的版本号、Content-Type文件类型、状态吗等。
以上需要了解一下各个状态吗所代表的含义,基本如下:
1xx:信息响应类,表示接收到请求并且继续处理
2xx:处理成功响应类,表示动作被成功接收、理解和接受
3xx:重定向响应类,为了完成指定的动作,必须接受进一步处理
4xx:客户端错误,客户请求包含语法错误或者是不能正确执行
5xx:服务端错误,服务器不能正确执行一个正确的请求 假如要分门别类那确实有很多,我就不一一列举了,可以看[这篇文章](http://zh.wikipedia.org/wiki/HTTP%E7%8A%B6%E6%80%81%E7%A0%81)。
上面的resource其实就相当于解析后的路径,所以我们要对在此路径下的资源进行解析,代码如下:
boolean checkResource(String resource,Socket socket) throws IOException {
boolean bool = false;
PrintStream out = new PrintStream(socket.getOutputStream(), true);
File file = new File("F:\\" + resource);
System.out.println(file);
if (file.exists() && file.isDirectory()) {
file = new File("F:\\" + resource + "\\" + "index.html");
if (file.exists()) {
out.println("HTTP/1.1 200 OK");// 成功返回
out.println("Content-Type:text/html;charset=GBK");
out.println("Content-Length:" + file.length());// 返回内容字节数
out.println();// 根据 HTTP 协议, 空行将结束头信息
FileInputStream fis = new FileInputStream(file);
byte data[] = new byte[fis.available()];
fis.read(data);
out.write(data);
out.close();
fis.close();
bool = true;
}
} else if (file.exists() && file.isFile()) {
file = new File("F:\\" + resource + "\\" + "index.html");
if (file.exists())
bool = true;
} else {
PrintWriter outhtml=new PrintWriter(socket.getOutputStream(),true);
outhtml.println("HTTP/1.1 404 Not found");
outhtml.println("Content-Type:text/html;charset=GBK");
outhtml.println("Content-Length:" + file.length());
outhtml.println();
outhtml.println("<h1>404 The file is not exist!</h1>");
outhtml.close();
bool = false;
}
return bool;
}
上面的内容无非就是这个意思:
1、假如用户输入的是类似于localhost:80/webapp则浏览器显示一个页面,假如输入是的是localhost:80/webapp/test则显示此项目下的主页面;假如,没有资源,则输出未找到页面。
下面,我们来运行这段程序:
public static void main(String[] args) {
new SingleServer();
} 同时我们在浏览器中输入`localhost:80/webapp`和`localhost:80/webapp/test`看截图显示如下:
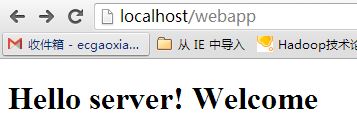
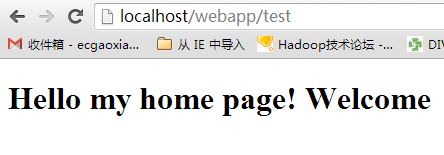
以上的一个小型web服务器算是完成了,但是还有很多地方需要去进行润色,比如如何处理并发访问,如何使相关信息通过配置的方式使其更灵活,tomcat中解析jsp、servlet是如何做到的,如何对类似velocity模板引擎中的标签进行解析、页面缓存的策略等等内容,这些都是需要去好好思考的,而且思考越多,获得的也越多。
(未完)
###参考资料
2、Http权威指南
3、超文本传输协议
4、http状态码