在自然语言处理的过程中,我们通常都需要对语句、词汇进行处理,从而通过向量的方式去表示词所在的位置甚至词和词之间的关系。
一、 Word Embedding 的含义
主要指【词嵌入】,其实就是将词在向量空间中进行映射,按照我个人的理解就是将最原始的one-hot向量映射为一个更稠密的连续向量,并通过一个语言模型去学习这个向量的权重,而这个更稠密的连续向量也被称为分布式表示,处理的这个过程叫做Embedding过程。
Word Embedding 是自然语言处理中一种语言模型和特征学习技术,这些技术会把词汇表中的单词或是短语映射成由实数构成的向量上。
二、 Word Embedding 的类型
第一种,基于计数的方法
1、BOW 词袋模型 这是最简单的映射方法,属于one-hot。 什么是one-hot类型,举个例子,比如我有一个句子:I like my home,如果要对这句话中的词汇进行向量表示,我们可以采用如下方式:
1 0 0 0
0 1 0 0
0 0 1 0
0 0 0 1
如上,第一行行向量就可以表示”I”,第二行可以表示”like”,以此类推…… 其中向量的size代表词汇的长度,向量某个位置的值指代这个单词是否出现。
但如上的表示方法其实也有一些缺点: 1、因为所形成的矩阵属于非常稀疏,真实的值远小于实际的值,而真实训练过程中其实会涉及非常大的预料,那么所涉及的矩阵点乘所占用的内存空间会很大; 2、每一个向量和另外一个向量之间正交(向量与向量之间乘积为0),无法去表现词之间的关系
2、n-gram 模型
n-gram模型基于一个假设,第n个词出现与前n-1个词相关,而与其他的词不相关。整个句子出现的概率就等于各个词出现概率的乘积。 可以以如下联合概率来进行表示:P(W)=P(w1,w2,w3,…wn)=P(w1)P(w2|w1)P(w3|w1,w2)P(W4|w1,w2,w3)… n-gram有如下的特点: 1、某个词的出现依赖于其他若干词; 2、我们获得的信息越多,预测越准确 但也有如下缺点: 1、参数空间过大,会导致参数计算非常巨大; 2、数据非常稀疏 因为如上的缺点,后来引入了马尔可夫假设:一个词的出现,仅仅与之前的几个词有关系。 正常对n-gram的分类可以有bi-gram、tri-gram,但都因为参数空间过大以及数据稀疏的问题,导致在计算和资源使用效率上不尽人意。
3、共现矩阵Cocurrence matrix
根据窗口内的单词的共现关系来生成词向量,最后得到的共现矩阵,值为两个词作为邻居同时出现在窗口的次数。 我们还是以 I like my home这句话为例子,如果用共现矩阵来进行表示,如何进行呢?
I like my home
I 0 1 0 1
like 1 0 1 0
my 0 1 0 1
home 0 0 1 0
如上,通过窗口的方式,就能够词之间的关系。但其也有一定的缺点: 1、当词的数量巨大的时候,有维度灾难; 2、当词袋中有新的词汇进入的时候,很难去对矩阵进行添加和扩展 在日常使用共现矩阵进行语言模型的构成的时候,面对维度灾难,我们通常都会去进行降维,比如通过SVD奇异值分解或者PCA主成成分分析等方法,进行特征维度下降。
第二种,基于预测的方法
这里主要就是指Word2Vec,其是通过神经网络的方式来完成Word Embedding。
其最初是通过一个前馈神经网络来预测一个词出现的概率分布。整个模型如下图所示:
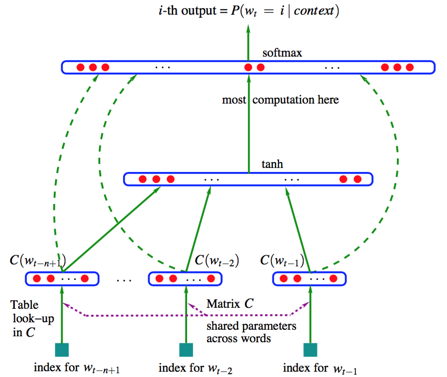
这就是以前NNLM模型。
这里介绍两种模型算法,第一种CBOW,第二种skip-gram。
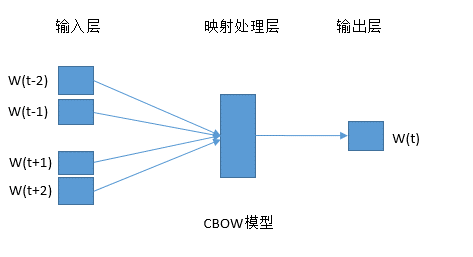
什么是CBOW?我们还以I like my home为例子,假如,我将这句话改为I _ my home,从而预测 _ 是like的概率。 这种方式就是通过一个句子的上下文,从而预测目标词。模型可以用如下图所示:
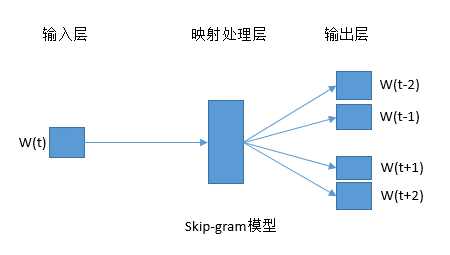
那什么是skip-gram呢?正好相反。 比如我将I like my home改成_ like _ home,从而预测like之前和之后出现哪些词的概率最大,这个就是通过目标词去预测上下文。
如上两种方式的预测就会通过神经网络去进行完成。
后面会详细介绍这几种方式。
(完)
—————–EOF——————